Prev
"Future is Now" - an AI Made Video
A promotion video to showcase the potential of AI-assisted media production.
10.2024
Project Brief
In this project, I led a team to create a promotional video for Data Enlighten Technology Co., Ltd. The video tells a cohesive story using AI-generated content, showcasing how the company’s intelligent insurance product can enable future electric vehicles to automatically assess and process collision damage.
We began by storyboarding the scenes, characters, and activities for the video. Using the FLUX generative model and ComfyUI, I created over 400 still images, then I used Kling and Runway AI to convert them into 50 high-quality video clips. Finally, I composed the AI clips into the completed video.
The final videos were used by 10+ electric vehicle manufacturers and 20+ insurers, with them expressing interest in promotion.
Project Info
Context: Group Professional Video Project
Category: AI-generated Video
Tools Used: Generative AI Models, Davinci Resolve Studio, TTS Maker, ComfyUI, Runway, Kling AI, Adobe Creative Suite
Client Companies(Electric Vehicle): BYD, NIO, Li Auto, XPeng Motors, GWM
Project Chief Client:
Mr. Kai, Zhou
Mr. Kenny, Liao
Collaborators:
Weiyi, Zhang(ME) Rizhang, Sun Monica, Gao Wei, Li Tong, Shen Min, Hao
My Role: Generative-AI design, technology research, video production, CG animation
Production Idea & Process
The Storyboard Prompts
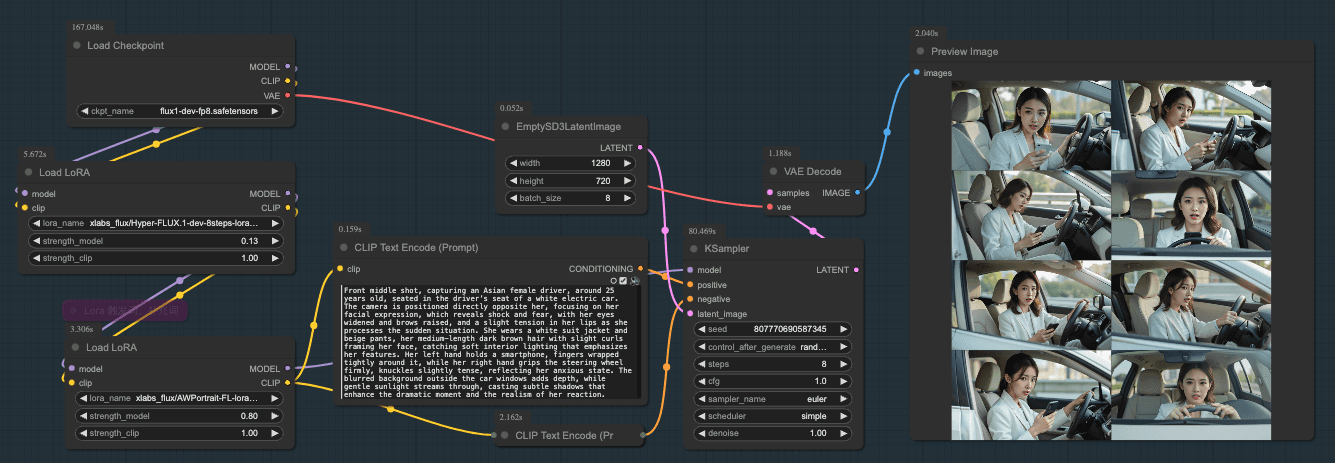
Before generating the AI clips for the video, we firstly went through a comprehensive storyboarding on what kind of scenes, characters and activities will be appearing in the video. Then, I classified all the scenes into a chart containing detailed information to be used as text prompts for effective and high-quality image generation.
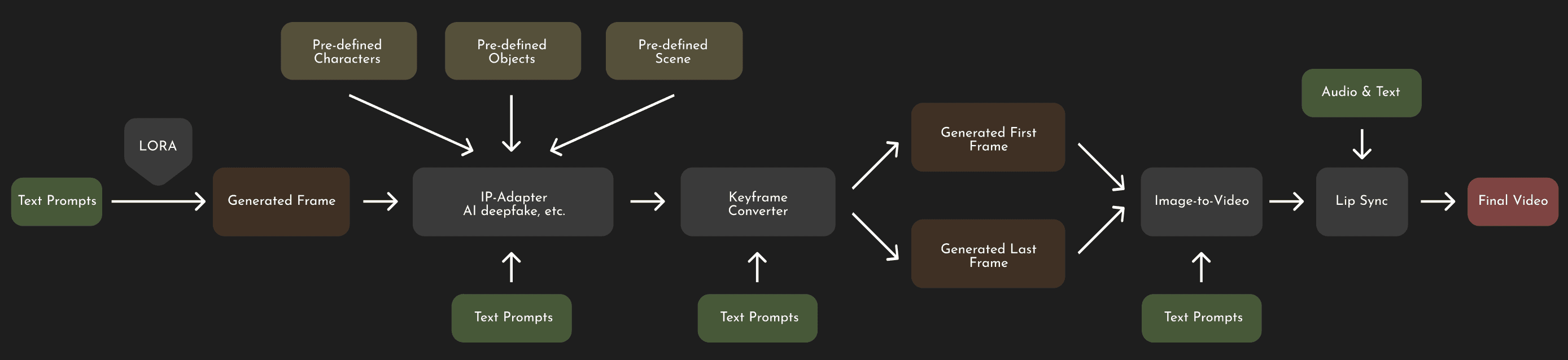
The Generation Workflow
I researched the possible workflows for AI video generation, and to ensure the quality and consistency, the contemporary best workflow is using text prompt to get high-quality still images via the popular text-to-image model like FLUX, and then convert the images with nicely tuned text prompts to obtain the video using image-to-video model like AnimaDiff, or AI video platforms such as Runway or Kling.

The Challenging Part
The most challenging part is the inconsistency and uncertainty in generation. Due to the nature of diffusion models, each image will result in certain differences in their details. To minimize the influence of this, I used well-defined text prompts and generated more than 400 images. Then I leveraged my videography skills to screen and compose each image cutscene to ensure they are logically fluent and visually cohesive

Outcome
By several times of trial and error, I eventually obtained around 50 usable video clips, and then composed the final video according to the scripts. I also made several animations for the video to illustrate the UI workflow of the intelligent system.
Future Improvements
Due to limited production time, the video, while generally successful, has some flaws, such as imperfect lip sync and minor inconsistencies in scene details. To improve this, a more powerful workflow could be developed, streamlining the image generation process and incorporating character-face adaptation to ensure scene consistency. Additionally, a lip sync process could be applied before finalizing the video.